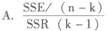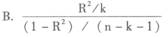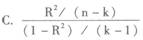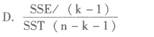题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
一元回归方程其斜率系数对应的t统计量为2.00,样本容量为20,则在5%显著性水平下,对应的临界值及显
一元回归方程
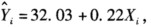 其斜率系数对应的t统计量为2.00,样本容量为20,则在5%显著性水平下,对应的临界值及显著性为()。
其斜率系数对应的t统计量为2.00,样本容量为20,则在5%显著性水平下,对应的临界值及显著性为()。
A.临界值为1.734,系数显著不为零
B.临界值为2.101,系数显著不为零
C.临界值为1.734,系数显著为零
D.临界值为2.101,系数显著为零
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
一元回归方程
其斜率系数对应的t统计量为2.00,样本容量为20,则在5%显著性水平下,对应的临界值及显著性为()。
A.临界值为1.734,系数显著不为零
B.临界值为2.101,系数显著不为零
C.临界值为1.734,系数显著为零
D.临界值为2.101,系数显著为零
如果结果不匹配,请 联系老师 获取答案
 更多“一元回归方程其斜率系数对应的t统计量为2.00,样本容量为2…”相关的问题
更多“一元回归方程其斜率系数对应的t统计量为2.00,样本容量为2…”相关的问题
表2-1列出了中国1978—2000年的财政收入Y和国内生产总值GDP的统计资料。要求,以手工和运用EViews软件(或其他软件):
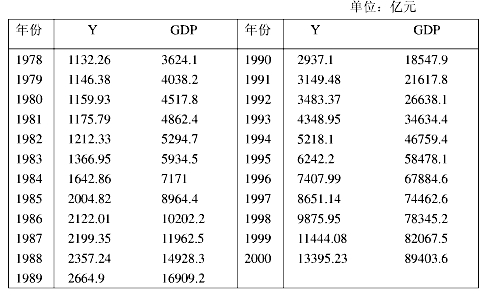
(1)做出散点图,建立财政收入随国内生产总值变化的一元线性回归方程,并解释斜率的经济意义;
(2)对所建立的回归方程进行检验;
(3)若2001年中国国内生产总值为105709亿元,求财政收入的预测值及预测空间。
表3-1为有关经批准的私人住房单位及其决定因素的4个模型的估计量和相关统计值(括号内为p-值,即以对应的t统计量为临界值的置信度α)(如果某项为空,则意味着模型中没有此变量)。数据为美国40个城市的数据。模型如下:
Y=β0+β1X1+β2X2+β3X3+β4X4+β5X5+β6X6+β7X7+μ其中,Y为实际颁发的建筑许可证数量,X1为每平方英里(1平方英里=2.59平方千米)的人口密度,X2为自有房屋的均值(单位:百美元),X3为平均家庭的收入(单位:千美元),X4为1980—1992年的人口增长百分比,X5为失业率,X6为人均交纳的地方税,X7为人均缴纳的州税。
表3-1 | ||||
变量 | 模型A | 模型B | 模型C | 模型D |
C | 813(0.74) | 392(0.81) | -1279(0.34) | -973(0.44) |
X1 | 0.075(0.43) | 0.062(0.32) | 0.042(0.47) | |
X2 | -0.855(0.13) | -0.873(0.11) | -0.994(0.06) | 0.778(0.07) |
X3 | 110.41(0.14) | 133.03(0.04) | 125.71(0.05) | 116.60(0.06) |
X4 | 26.77(0.11) | 29.19(0.06) | 29.41(0.001) | 24.86(0.08) |
X5 | -76.55(0.48) | |||
X6 | 0.061(0.95) | |||
X7 | -1.006(0.40) | -1.004(0.37) | ||
RSS | 4.763×107 | 4.843×107 | 4.962×107 | 5.038×107 |
R2 | 0.349 | 0.338 | 0.322 | 0.312 |
hat{sigma }^2 | 1.488×106 | 1.424×106 | 1.418×106 | 1.399×106 |
AIC | 1.776×106 | 1.634×106 | 1.593×106 | 1.538×106 |
1)检验模型A中的每一个回归系数在10%水平下是否为零(括号中的值为双边备择p-值)。根据检验结果,你认为应该把变量保留在模型中还是去掉?
(2)在模型A中,在10%水平下检验联合假设H0:bi =0(i=1,5,6,7)。说明被择假设,计 算检验统计值,说明其在零假设条件下的分布,拒绝或接受零假设的标准。说明你的结论。
(3)哪个模型是“最优的”?解释你的选择标准。
(4)说明最优模型中有哪些系数的符号是“错误的”。说明你的预期符号并解释原因。确认 其是否为正确符号
设线性调频矩形脉冲信号为
其中,为矩形函数;μ为调频系数。线性调频信号的包络是宽度为τ的矩形脉冲;信号的瞬时频率是随时间线性变化的。如果调频斜率为正,则如图所示。

线性调频信号的瞬时频率为
在脉冲宽度τ内,信号的角频率由变化到
;调频带宽
;其重要参数时宽带宽积D为
现考虑信号s(t)的匹配滤波问题。假定线性时不变滤波器的输入信号为
x(t)=s(t)+n(t)
其中,n(t)是均值为零、功率谱密度为Pn(ω)=No/2的白噪声。
(1)求线性调频信号的频谱函数S(ω)。
(2)求信号s(t)的匹配滤波器的系统函数H(ω)。
(3)求信号s(t)的匹配滤波器的输出信号so(t)和输出的功率信噪比SNRo。
设总体X~N(0,1),由X得到容量为5的样本X1,X2,…,X5,试求常数c,使统计量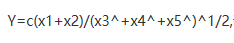 服从t分布,并确定其自由度
服从t分布,并确定其自由度
有人根据美国1961年第一季度至1977年第二季度的季度数据,得到了如下的咖啡需求函数的回归方程:
lnQ?t
(-2.14) (1.23) (0.55)
0.01T-0.10D1t-0.16D2t-0.01D3t
(3.36)(-3.74) (-6.03) (-0.37)
R2=0.80
其中,Q为人均咖啡消费量(单位:磅),P为咖啡的价格(以1967年价格为不变价格),P'为茶的价格(1/4磅,以1967年价格为不变价格),T为时间趋势变量(1961年第一季度为1……1977年第二季度为66);

回答下列问题:
(1) 模型中P、I和P?系数的经济含义是什么?
(2) 咖啡的价格需求是否很有弹性?
(3) 咖啡和茶是互补品还是替代品?
(4) 如何解释时间变量T的系数?
(5) 如何解释模型中虚拟变量的作用?
(6) 哪一个虚拟变量在统计上是显著的(0.05)?
(7) 咖啡的需求是否存在季节效应?
某市房地产投资公司出售的五个楼盘面积与总售价资料如下:
楼盘面积 (平方百米) | 9 | 15 | 10 | 11 | 10 |
总售价 (千元) | 36 | 80 | 44 | 55 | 35 |
要求:(1)分析楼盘总面积与楼盘总售价之间是否存在相关关系,计算相关系数。
(2)建立一元线性回归方程。
(3)判断模型的拟合优度。
(4)以90%置信度估计楼盘总面积为20平方百米时,其总售价的平均值的置信区间。
设随机变量X1,X2,…,Xn是来自正态总体X~N(μ,σ2)的样本,则()是统计量。
A.y=3000+x
B.y=4000+x
C.y=4000+4x
D.y=3000+4x
设总体X服从正态分布N(u,σ2)(σ>0),从该总体中抽取随机样本X1,X2,…,X2n(n≥2),其样本均值为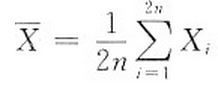 ,求统计量
,求统计量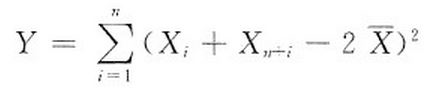 的数学期望
的数学期望
设ξ~N(μ,σ2),其中μ为已知,σ2未知,(ξ1,ξ2,…,ξn)是总体ξ的样本,问下列哪些是统计量,哪些不是?并简述其理由.
(1)ξ1+ξ2+σ;
(2)
(3)min{ξ1,ξ2,ξ3};
(4)
(5)
(6)